vLLM 사용 방법

vLLM 사용 방법
vllm을 사용하기 위해서는 huggingface의 계정과 경우에 따라 LLM 모델의 리포지토리 사용 허가가 필요하며 원할한 사용을 위해서는 vLLM의 옵션에 관해서도 숙지가 필요합니다. 한국어에 능통했던 LLM 모델과 사양은 아래와 같습니다.
- 운영체제 : Ubuntu 24.04
| 모델 | 파라미터 크기 | GPU VRAM 권장사양 | 명령어 |
|---|---|---|---|
| Gemma3 | 12B | 48GB | vllm serve "google/gemma-3-12b-it" |
| Gemma3 | 27B | 96GB | vllm serve "google/gemma-3-27b-it" |
| Phi4 | 14B | 48GB | vllm serve "microsoft/phi-4" |
vLLM에 여러 방법으로 사용되는 옵션입니다.
| 옵션 | 설명 |
|---|---|
| --trust-remote-code | Hugging Face 저장소에 있는 모델의 Python 코드 실행 허용 |
| --port 8080 | API 포트 변경 (기본값 : 8000) |
| --gpu-memory-utilization 0.95 | 사용 가능한 GPU 메모리 설정(%) 과도할 경우 OOM 에러 발생 (기본값 : 0.9) |
| --tensor-parallel-size 4 | 모델을 4개의 GPU에서 병렬 처리 (기본값 : 1) |
| --max_model_len 1024 | 모델이 한 번에 처리할 수 있는 최대 토큰 길이 설정 (기본값 : 2048) |
| --quantization bitsandbytes | 모델을 양자화하여 메모리 절약 |
| --load-format bitsandbytes | 모델의 저장 및 로드 방식을 bitsandbytes 포맷으로 설정 |
| --download-dir /data/models | 모델 다운로드 위치를 일시적으로 변경하여 저장 |
1. LLM 모델 실행
LLM 모델 실행 전에 Hugging Face 계정 토큰의 생성 또는 확인이 필요합니다.
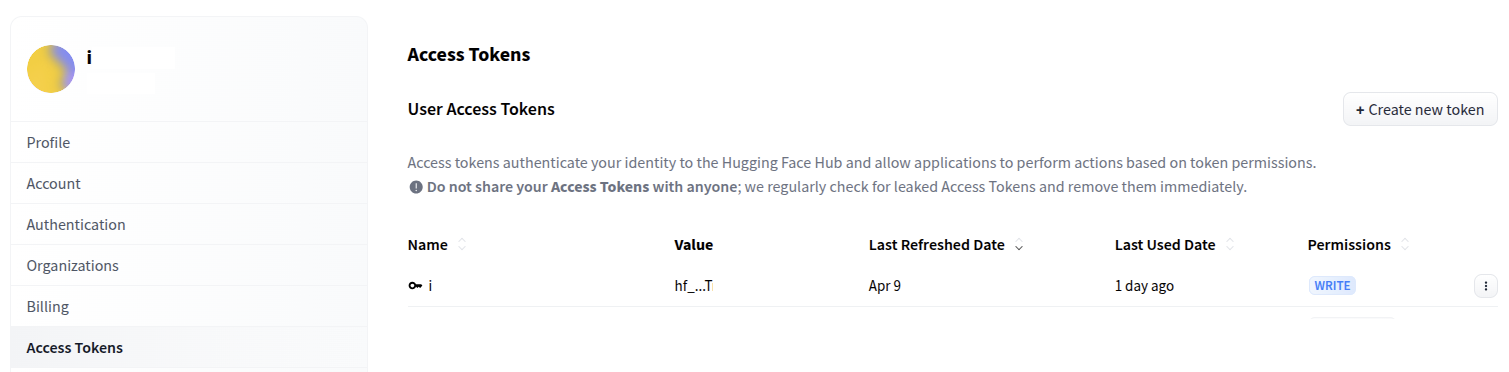
파이썬의 가상환경을 적용하고 Hugging Face로 로그인을 진행합니다.
source /iwinv_venv/bin/activate
huggingface-cli login
A token is already saved on your machine. Run `huggingface-cli whoami` to get more information or `huggingface-cli logout` if you want to log out.
Setting a new token will erase the existing one.
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens
Enter your token (input will not be visible): 토큰 값 입력
Add token as git credential? (Y/n) n
Token is valid (permission: write).
The token `i` has been saved to /vLLM_llm/huggingface/stored_tokens
Your token has been saved to /vLLM_llm/huggingface/token
Login successful.
The current active token is: `i`
vLLM 명령어를 통해 LLM 모델을 실행합니다. 활성화 되기전까지 수 분의 시간이 소요됩니다.
vllm serve "microsoft/phi-4"
활성화 되면 아래와 같이 대기상태가 됩니다.
INFO: Started server process [99690]
INFO: Waiting for application startup.
INFO: Application startup complete.
별도의 터미널을 실행 후 curl을 통해 질문을 남겨보겠습니다.
curl -X POST "http://localhost:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "microsoft/phi-4",
"prompt": "대한민국의 수도가 어디야? 간단히 설명해줘",
"max_tokens": 300
}'
조금 기다리면 아래와 같은 답변과 성능에 관련된 내용을 확인할 수 있습니다.
{"id":"cmpl-g468ahg4erw8a6ha4g86ewa486hj83y4","object":"text_completion","created":1749709512,"model":"microsoft/phi-4","choices":[{"index":0,"text":". <|end|\r\n|out|한국의 수도는 서울입니다. ,"logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":27,"total_tokens":327,"completion_tokens":300,"prompt_tokens_details":null},"kv_transfer_params":null}
3. LLM 모델 다운로드
LLM 모델만을 다운로드 받고 싶을 경우 huggingface-cli을 통해 진행할 수 있습니다.
huggingface-cli download microsoft/phi-4
- LLM 모델 다운로드 시 참고 사항
-
- 환경변수로 디렉토리를 지정 했다면 /vLLM_llm/huggingface/hub에 LLM 모델이 저장됩니다.
-
- 별도로 디렉토리를 지정하지 않았다면 /root/.cache/huggingface/hub 디렉토리에 저장됩니다.
vLLM은 LLM 모델 삭제 명령어를 지원하지 않아 필요한 경우 rm을 통해 별도로 삭제를 진행해야 합니다.
Open WebUI와 연동하여 사용
Open WebUI에서 vllm을 연동해서 사용하려면 몇가지 준비 과정이 필요합니다. 먼저 서버에��서 8080 포트가 활성화 되어있는지 확인합니다.
netstat -nltp
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 41666/python3
만일 8080 포트가 확인되지 않는다면 Open WebUI 서비스의 상태 체크가 필요합니다.
systemctl status openwebui.service
Open WebUI에서 vllm을 자동으로 연동하지 않으므로 터미널에서 지속적으로 실행이 되어있어야하며 해당 콘솔에서 답변에 관련된 토큰 값을 확인할 수 있습니다.
vllm serve "microsoft/phi-4"
1. Web 접속
http://xxx.xxx.xxx.xxx:8080
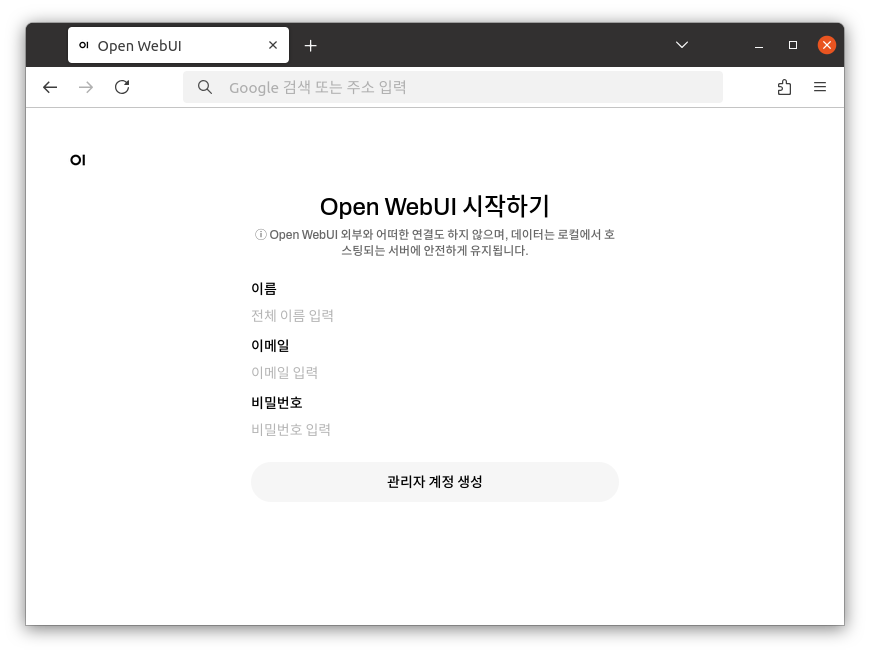
2. 계정 생성
관리자가 될 계정정보를 입력 후 관리자 계정 생성을 클릭합니다.
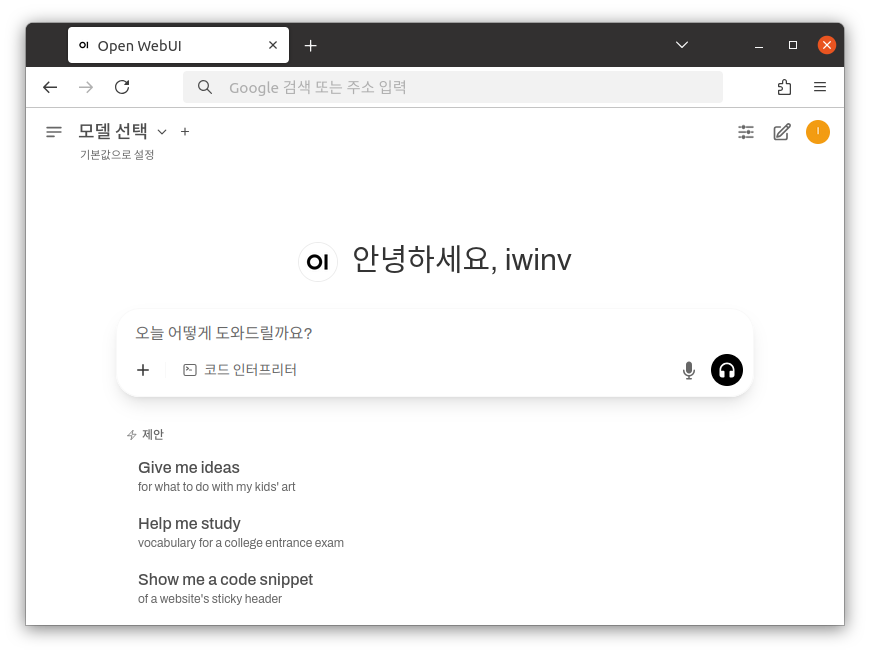
3. 로그인 후 첫 화면
vLLM과 연동이 되어있지 않다면 모델 선택에서 내용을 확인할 수 없습니다.
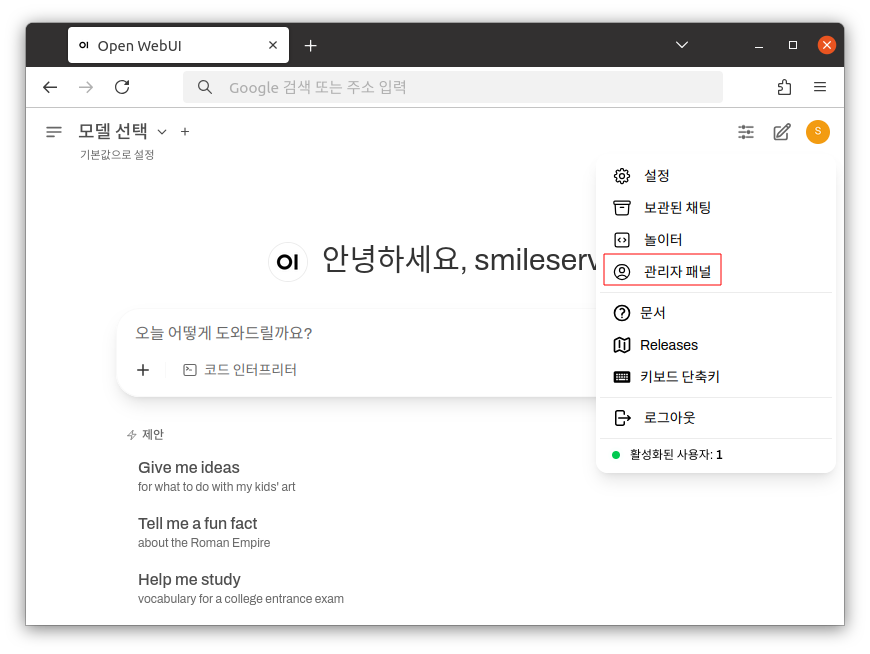
4. vLLM 연동
좌측 상단에 유저 아이콘을 클릭 후 사용자 패널로 이동합니다.
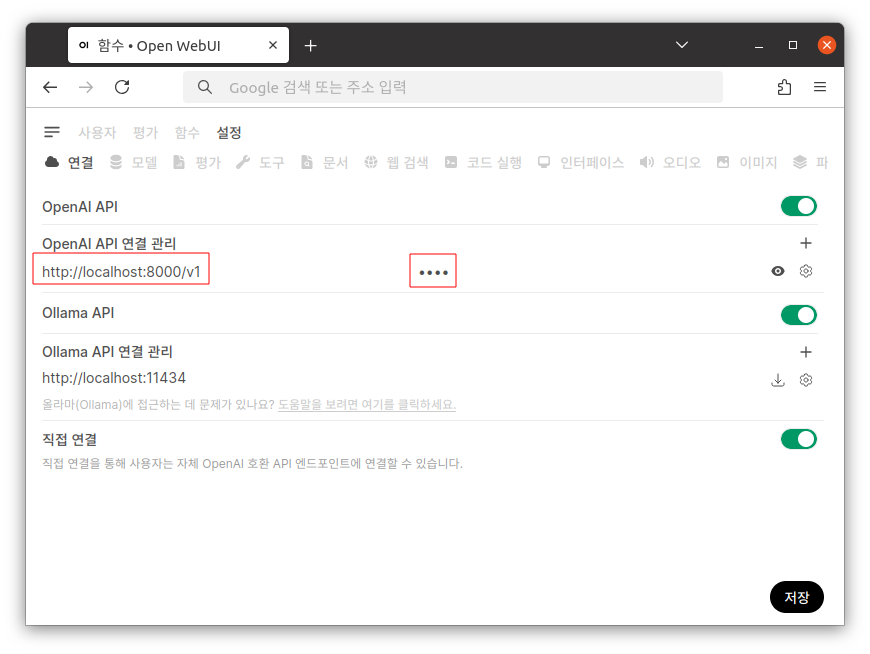
OpenAI API 연결 관리에서 아래와 같은 내용을 입력하고 저장합니다.
URL : http://localhost:8000/v1
비밀번호 : �임의의 값
5. LLM 모델 사용
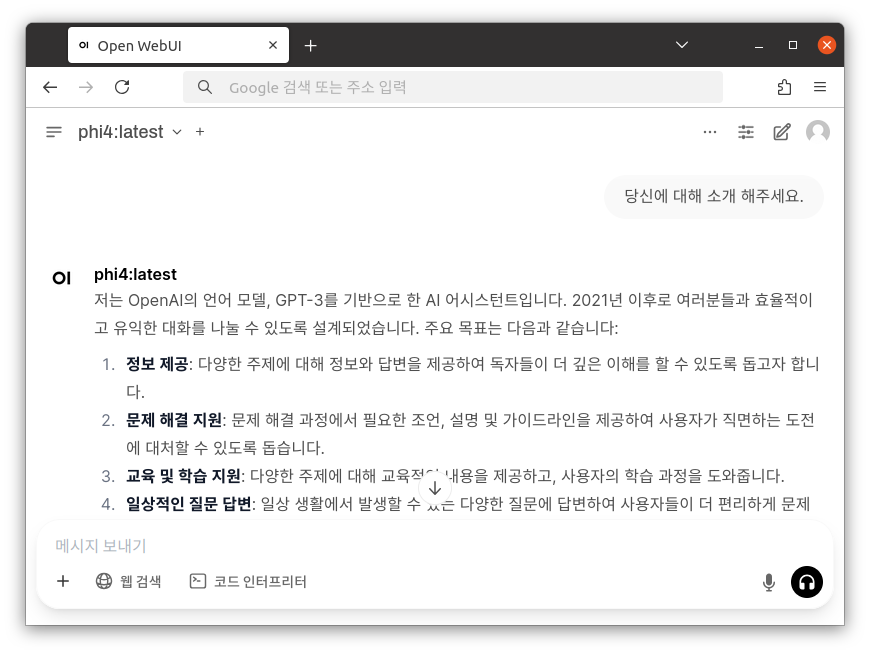
처음으로 돌아가면 실행된 LLM 모델로 설정된 부분을 확인할 수 있고 질문을 남길수 있습니다.
토큰 등의 결과 값은 LLM 모델이 작동 중인 터미널에서 확인이 가능합니다.
INFO: Started server process [99690]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO 06-12 15:27:20 [loggers.py:118] Engine 000: Avg prompt throughput: 2.7 tokens/s, Avg generation throughput: 0.2 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.1%, Prefix cache hit rate: 31.0%
방화벽 사용 권장
서버와 Open WebUI에 기본적으로 사용되는 22, 8080 포트에 불필요한 외부 접근을 막고 안정적인 사용을 위해서 자체적인 설정 또는 매뉴얼 통한 방화벽 설정을 적용하여 사용할 것을 권장합니다.