LLM 최적화, GPU서버 출시

“비싼 HBM GPU 없어도 OK!”
“보급형 GPU의 수평 확장을 통해 합리적 비용으로 많은 VRAM을 확보하세요!
“소규모 기업도 부담 없이 LLM 개발에 도전할 수 있습니다”
서버 비용 허리 휠 때, 반값서버! 스마일서브입니다.
LLM을 도입하고 싶지만, 서버 비용, 성능, 안정성 이슈로 망설이셨던 분들을 위해 준비했습니다.
우선 Ollama는 NVIDIA뿐 아니라 AMD 등 다양한 하드웨어를 지원하는 유연한 프레임워크입니다.
VRAM이 부족한 경우 CPU와 DRAM을 보조 자원으로 활용하여, 소형~초대형까지 다양한 LLM 서비스를 구동할 수 있습니다.
소형 LLM이라면 내장 GPU만으로도 운용이 가능할 만큼 실용적입니다.
이러한 흐름에 맞춰 Ollama, vLLM 등의 프레임워크에 최적화된 GPU 서버를 새롭게 출시했습니다.
또한 기존 GPU 서버들도 일부 리뉴얼하여 더 나은 성능과 효율을 제공합니다.
어떤 변화가 있었는지 지금 확인해 보세요!
신제품 핵심 요약
- 다양한 형태의 서버 : 가상 서버, 베어메탈 서버, 사양 맞춤형 서버
- 대용량 LLM 최적화 : Gemma3 27B, DeepSeek-R1 671B 등의 안정적 구동 지원
- 프레임워크 설치 : Ollama, vLLM, Ktransfomers 등 설치 서비스
- 반값 이상 저렴한 비용 : 글로벌 CSP 대비 최대 1/3 저렴한 서비스 가격
왜 스마일서브 GPU 서버인가요?
딥러닝과 LLM은 병렬 연산 성능과 안정성이 핵심입니다.
스마일서브 GPU 서버는 ECC 메모리, 48GB 이상의 GPU VRAM, 고속 GDDR7 메모리, 그리고 최신 RT 및 텐서 코어 기반 아키텍처를 갖춘 GPU를 통해 안정적인 학습 및 추론 환경을 제공합니다.
이번에 선보인 GPU 서버는 대표적으로 Gemma3 27B와 DeepSeek-R1 671B 모델을 안정적으로 구동할 수 있도록 설계되었습니다.
- 가상 서버: GPU 패스스루 기반의 클라우드 가상 서버
- 베어메탈 서버: 하드웨어 자원을 단독 사용하는 온디맨드 방식의 서버
- 맞춤형 서버: GPU, CPU, RAM, STORAGE 등 사양 선택이 자유로운 서버
주요 사양 및 옵션은?
| 항목 | 구성 예시 |
|---|---|
| GPU | 4000Ada, A6000, 6000Ada, PRO5000, PRO6000, AMD W6800 등 (iwinv: 최대 4개 / CLOUDV: 최대 8개 장착 가능) |
| CPU | 최대 2개 장착 가능 |
| RAM | 최대 32개 ��장착 가능 |
| 스토리지 | 최대 12개 장착 가능(SSD 기본, 확장 가능) |
| 프레임워크 | vLLM, Ollama, Ktransformers |
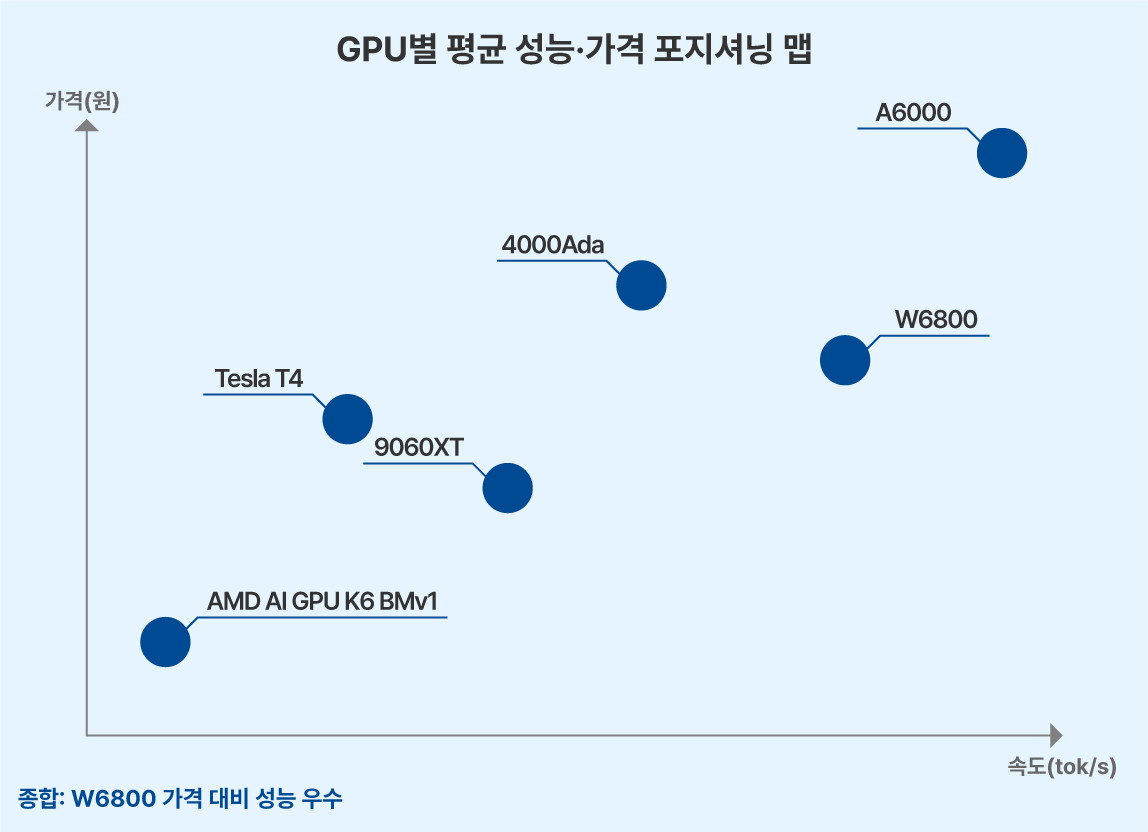
특히 AMD Radeon Pro W6800은 Ollama 공식 지원 GPU로써, 성능과 가격 경쟁력이 매우 뛰어납니다.
(8 Multi-GPU는 cloudv에서 신청 가능합니다. Cloudv 바로가기)
LLM 구축을 위한 강력한 성능
딥러닝과 LLM은 병렬 연산 성능과 안정성이 핵심입니다.
GPU 모델별 LLM 모델의 벤치마크 결과는 아래 링크에 자세히 작성해 놓았으니 참고해주세요.
아울러 NVIDIA에서 올해 초 새롭게 선보인 PRO5000, PRO6000도 서비스 도입도 앞두고 있습니다.
 Gemma3 27B (Q4_K_M) 기준 테스트 결과
Gemma3 27B (Q4_K_M) 기준 테스트 결과
- Gemma3 27B: 128k 컨텍스트 길이와 우수한 다국어 처리 성능, 특히 한국어 특화
- DeepSeek-R1671B: GPT-4에 근접한 성능, 복잡한 계산·코딩·응답 품질 우수
| 모델 | 매개변수 | DRAM 최소 사양 | 실행 환경 |
|---|---|---|---|
| 초소형 | ~ 2B 파라미터 | 4 ~ 8GB | 노트북 수준의 GPU 또는 일부 CPU-only 환경에서도 실행 가능 |
| 소형 | 2B ~ 10B 파라미터 | 8 ~ 16GB | 일반 소비자용 GPU 가능 4090등 |
| 중형 | 10B ~ 20B 파라미터 | 16 ~ 32GB | 4000Ada 이상 또는 RTX 4090/5090 Multi-GPU 구성 |
| 대형 | 20B ~ 70B 파라미터 | 32 ~ 128GB | A6000, PRO5000 Multi-GPU 구성 |
| 초대형 | 70B ~ 파라미터 | 128GB 이상 | PRO6000 Multi-GPU 구성 이상 |
스마일서브 IDC-SMILE [가산센터]
스마일서브 GPU 서버는 자사 IDC에 최적화되어 있고, 맞춤형 GPU 서버의 경우 상호 협의에 따라 별도 공간에 구축을 지원해 드리고 있습니다.
- Tier 3의 IDC 환경 (항온항습, 이중 전원, 100G 네트워크 지원 등)
- 월 2,400GB 국내 트래픽 / 월 50GB 해외 트래픽 기본 제공
- 초과 시 할인 요율 적용
- 연중무휴 99.9% 가동률
가성비 비교
서비스명 | 월 이용 요금 | |
|---|---|---|
| iwinv | 글로벌 A사 | |
| 4000Ada.G1 | 248,500원 | 777,480원 |
iwinv의 4000Ada.G1 GPU 서버 사용 시, 월평균 53만 원의 비용 절감 효과를 누릴 수 있습니다!
문의 및 신청
- 문의 전화 : 1688-4879
- 이메일 : cloud@iwinv.kr
오픈소스 기반 로컬 LLM 구축, 스마일서브 GPU로 시작해보세요!

반값서버는 iwinv
※ ‘반값서버’는 합리적인 가격과 안정적인 네트워크를 지향하는 iwinv의 슬로건입니다.